并发编程问题梳理

互斥锁(Exclusive Lock)是被最广泛支持的同步机制,编译器和多处理器会确保基于锁同步的多线程程序看起来就像是有多个同时执行的顺序线程。而一旦离开锁的庇护,程序员要么直面各种优化作用下的混乱世界,要么和实现同步原语(Synchronization Primitives)的系统工程师站在同一起跑线,捡起Memory Model这个更细粒度、更微妙的武器,在乱序优化的多线程世界中重建秩序。
——引用自https://github.com/GHScan
这是一篇学习笔记,帮助自己捋清楚并发编程中涉及的一些概念,在并发编程中会遇到的问题有:原子性问题、乱序问题、可见性问题。为了解决这些问题,从底层硬件架构到上层的高级语言为我们提供了工具或者保障:缓存一致协议(MESI)、原子指令、互斥锁、内存模型。
首先,讨论这些问题的前提一是多线程,二是存在共享变量。因为无论编译器和硬件如何优化都不会改变单线程中代码的编写和执行逻辑,否则咋编程呢,其次如果不存在共享变量,线程之间没有交集,如何调度和优化也无所谓。
原子性问题
原子性被破坏的原因
原子性,即一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。而由于操作系统的抢占式线程调度,会使得编程语言中的一个操作无法得到原子性的保证,看下面这个经典例子,多线程同时对一个共享变量执行++操作。
1
2
3
4
5
6
int cnt = 0;
void theadFunc()
{
cnt++;
}
通常编译器会把cnt++语句翻译成这 3 条指令。
- 把
cnt加载到某个寄存器中。 - 这个寄存器加一运算。
- 把寄存器的值写会内存。
由于调度、中断的存在,不同线程的这三条指令就会交织在一起,产生不定的排序,cnt++操作的原子性就无法得到保证,就会得到非预期结果。想要解决这个问题,就是想办法让这三条指令不被打断,让++的操作成为一个整体。
保证原子性的方法
方法一:原子性指令
现代CPU支持很多原子指令,我们只需要直接应用这些指令,比如原子加、原子减,原子读写等。比如使用c++11的atomic库封装好的数值变量,或者直接在C函数中按照特定的方式嵌入汇编代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//使用atomic库
std::atomic<int> cnt{0};
void theadFunc()
{
cnt.fetch_add(1, std::memory_order_relaxed);
}
//汇编实现:原子加上一个整数
static inline void atomic_add(int i, atomic_t *v)
{
__asm__ __volatile__("lock;" "addl %1,%0"
: "+m" (v->a_count)
: "ir" (i));
}
其中addl是一条原子指令,lock是CPU指令中的一个前缀,可以加在特定的指令前面,表示锁定内存的语意,确保同一时间只有一个CPU可以操作后面指令数据。单核心CPU是不需要lock前缀的,只要在多核心CPU下才需要加上lock前缀。
lock原理是锁定总线,有些情况下也可以优化为cache locking:
For the Intel486 and Pentium processors, the LOCK# signal is always asserted on the bus during a LOCK operation, even if the area of memory being locked is cached in the processor.
For the P6 and more recent processor families, if the area of memory being locked during a LOCK operation is cached in the processor that is performing the LOCK operation as write-back memory and is completely contained in a cache line, the processor may not assert the LOCK# signal on the bus. Instead, it will modify the memory loca- tion internally and allow it’s cache coherency mechanism to ensure that the operation is carried out atomically. This operation is called “cache locking.” The cache coherency mechanism automatically prevents two or more proces- sors that have cached the same area of memory from simultaneously modifying data in that area. –Intel® 64 and IA-32 Architectures Software Developer’s Manual 8.1.2.2
方法二:中断控制
原子操作只适合于单体变量,如整数。而一些用户自定义的数据结构有的可能有几百字节大小,其中可能包含多种不同的基本数据类型。这显然用原子操作无法解决。 想要让这三条指令不被打断,还有一个简单粗暴的办法就是控制中断,这个时候可以使用CPU的中断控制指令,CPU提供了开关中断的指令,x86CPU上关闭、开启中断有专门的指令,即cli、sti指令,在执行操作之前插入关闭中断指令,操作完成之后再打开。这样就保证了执行过程中不会被打断,保证了原子性。
但是注意这两条指令是特权指令,一般只有操作系统才会使用。
方法三:互斥锁
但是中断控制有局限性,那就是中断指令只能控制当前CPU,在多CPU多核心的系统下则无法保证原子性。这个时候就要使用编程语言或操作系统提供的锁这种工具,互斥锁(Exclusive Lock) 是被最广泛支持的同步机制,编译器和多处理器会确保基于锁同步的多线程程序看 起来就像是有多个同时执行的顺序线程。执行操作之前加锁,执行操作之后解锁。保证加锁区域操作的原子性:
1
2
3
4
5
6
7
8
int cnt = 0;
std::mutex mutex_;
void theadFunc()
{
mutex_.lock();
cnt++;
mutex_.unlock();
}
关于锁的话题是有很多内容的,这篇笔记不展开,只简单说互斥锁。互斥锁可以保证同一时间只有一个线程可以进入,其他线程等待或者阻塞。
互斥锁在底层的实现原理,其实就是需要一个状态位来标识是否加锁,多个线程来访问临界区时,需要先判断标识为是否已经加锁了,如果没加锁,自己将其加锁并进入执行。如果看到已加锁,就等待锁的释放,下面是一个自旋锁的流程示意图:
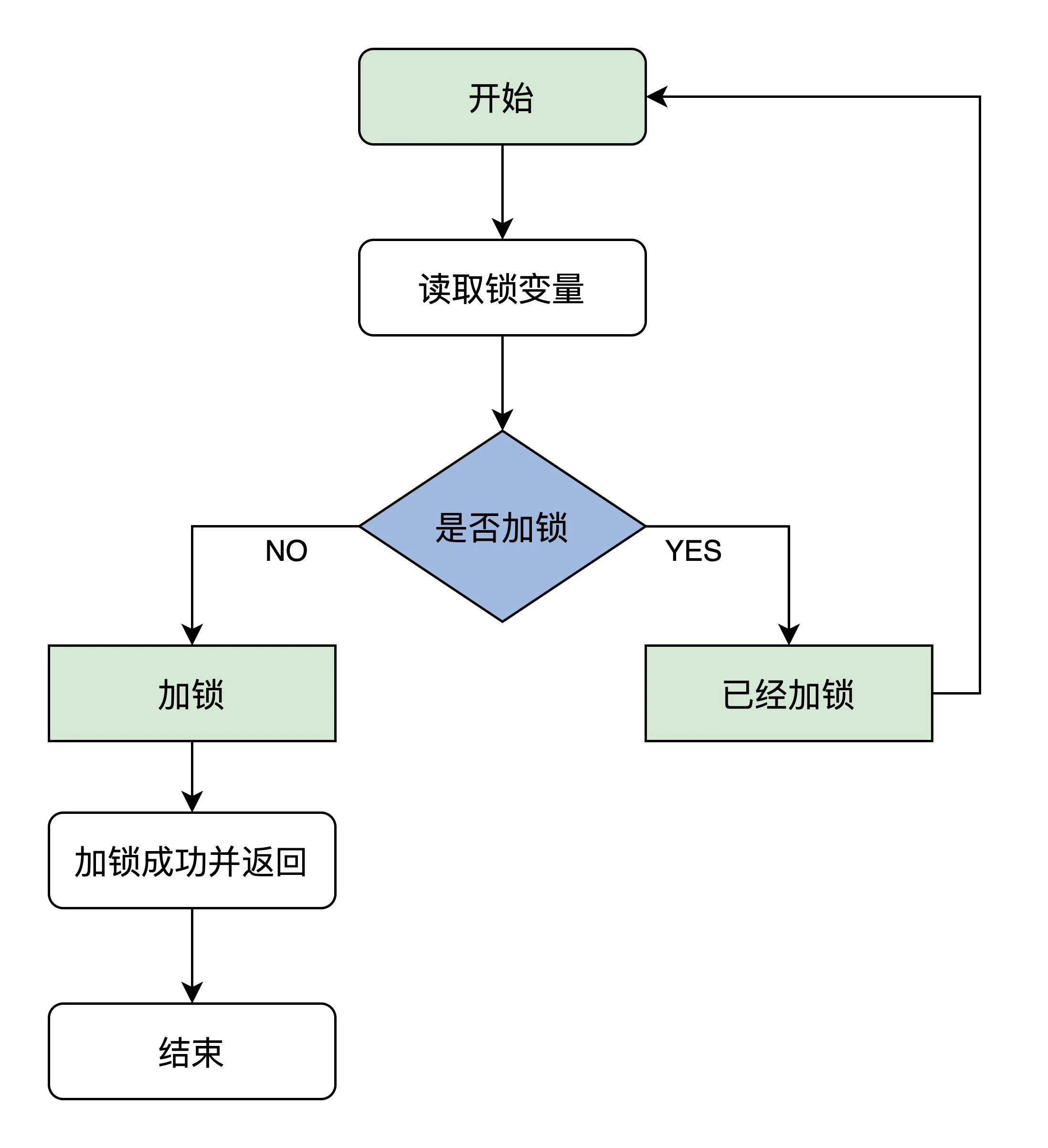
但是想要正确执行它,就必须保证读取锁变量和判断并加锁的操作是原子执行的,也就是上面的这句话:需要先判断标识为是否已经加锁了,如果没加锁,自己将其加锁,显然用if判断再赋值是无法保证原子性的。但是x86CPU给我们提供了一个原子交换指令,xchg,它可以让寄存器里的一个值跟内存空间中的一个值做交换,并且是原子操作,这样就保证了判断并加锁这个操作可以一次性完成。
比如说:锁用一个int值status表示锁的状态,0表示未加锁,1表示加锁。当多个线程同时尝试加锁时,使用1来交换status的值,得到结果为0的线程则加锁成功。因为1<->0这个交换只可能发生一次,其他线程得到的都是1<->1。这个指令也是CAS的实现原理。同时,这个指令即使不加lock前缀也自带lock语意:
The LOCK prefix is automatically assumed for XCHG instruction. –Intel® 64 and IA-32 Architectures Software Developer’s Manual 8.1.2.2
乱序问题与可见性问题
如今计算机使用的CPU,常见的就是SMP(Shared-Memory Multiprocessor),就是通过一个共享的地址空间进行通信和协调的多处理器系统。SMP又包括:
NUMA(Non-Uniform Memory Access):大量的处理器通过互连网络连接在一起,每个节点访问本地存储 器时延迟较短,访问其他节点有不同的延迟UMA(Uniform Memory Access):又叫SMP(Symmetric Multiprocessor),所有的处理器通过总线连接在一起,访问一个共享的存储器,每个节点的存储器访问延迟相同。目前常见的桌面多核处理器就是这种结构。
乱序的原因
引发乱序的原因总的来说就是编译器软件和底层硬件为了实现提升运行速度而做的一系列优化:
编译器优化
编译器会在不扰乱代码数据依赖的前提下,进行优化。主要可以包括重写编译指令的优化,比如
冗余代码消除、循环融合(Loop Fusion)、寄存器分配减少访问存储器的次数;指令调度,即调整指令顺序的优化。CPU优化
乱序执行:当前面的指令由于特种类型的功能单元不足、存储器延迟或操作 数没有计算出来,必须停顿时,CPU可以发射后续的无关指令,从而乱序执行。乱序指令有效的提高了 CPU利用率,掩盖了各种停顿。
写缓冲区(Write Buffer):CPU在写存储器时,不直接访问存储器或Cache,而是将要写的数据放入一 个写缓冲区,然后继续执行后面的指令,这缓解了写存储器导致的停顿。
失效队列 (Invalidate Queue):当处理器工作负载很高时,可能来不及处理、回应来自其他处理器的 Coherence Message,从而将等待回应的其他处理器阻塞,而利用一个消息缓冲区缓存这些请求并立刻 回应源处理器表示消息已收到,可以提高响应速度。
MESI
其中
写缓冲区和失效队列都与MESI有关,MESI是缓存一致性协议,由于每个CPU有独立缓存,当读写相同地址的数据时,需要通过缓存一致性协议来保持数据的一致性。MESI协议有专门的硬件支持,定义了四种状态以及状态之间的转换来实现,MESI就是四种状态的缩写,分别是:Modified、Exclusive、Shared、Invalid。举例:当一个Cache Line同时被多个处理器持有,其中一个处理器写,修改操作,这个时候就会向其他处理器发送Invalidate Message,令它们所持有的Cache Line失效。这样就达到了数据的一致性。但是等待其他所有处理器处理完
Invalidate Message并回应Acknowledge Message可能会等待几十上百个时钟周期,为了充分利用处理器,提高处理器指令吞吐量,引入了写缓冲区和失效队列。写操作的处理器可以不等待
Acknowledge Message,而先写到写缓冲区,并向下继续执行其他无关指令,收到Acknowledge Message后再从写缓冲区移除并写到Cache中。收到Invalidate Message不必马上处理,而是先放到失效队列中,在之后不忙或发生Cache Miss的时候再来处理。我觉得多处理器的缓存就是一个分布式缓存,引入了
写缓冲区和失效队列后实现的是最终一致性,而不是强一致性。导致了指令乱序和可见性的问题。
举个乱序的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int x = 0, y = 0;
int r1 = 0, r2 = 0;
void thread1Fun()
{
x = 1;
r1 = y;
}
void thread2Fun()
{
y = 1;
r2 = x;
}
从程序员的角度来讲:程序按照自己写的顺序执行,即使两个线程会交替执行。最终r1,r2的结果可能有下面几种,这些结果都是合理的,在我们的预期之内:
r1=1,r2=2r1=1,r2=0r1=0,r2=1
从系统的角度讲:为了最大化运行速度,r1=y可能会先于x=1执行,因为两个指令间没有依赖关系,所以系统认为可以乱序,r1=y,y=1,r2=x,x=1:因此会出现r1=0,r2=0这种不符合我们预期的结果。
内存模型
在单线程程序中,编译器的各种优化如冗余代码消除、 循环融合(Loop Fusion) 、指令调度等技术,会重写代码造成存储器访问顺序变化,而寄存器分配会改变存储器访问次数;类似的,处理器的乱序执行机制也会通过让后一条指令先执行,来掩盖前一条指令导致的流水线停顿和存储器停顿。尽管会改变不同地址存储器的访问顺序,但系统的这些优化对程序员是透明的,看起来程序仍然是在顺序执行。
然而在多线程程序中,编译器和多处理器并无手段自动发现多个线程间的协作关系,使得那些可能改变存储器访问顺序和次数的优化,同时对多个线程透明。没有程序员的帮助,要保持多线程程序的正确性,系统只能禁用这些作用在共享存储器上的优化,而这将严重损害性能。
为最大限度保留编译器和多处理器的优化能力,同时使多线程程序的执行结果是可预测的,系统需要程序员的帮助。最后的方案是,系统提供所谓Memory Model的规范,程序员通过规范中同步设施(各种内存屏障(Memory Barrier)和Atomic指令)来标记多个线程间的协作关系,使得不仅是单线程,系统的优化对多线程序也将透明。
Memory Model主要规定不同地址上的读写操作在其他处理器看来会否乱序(即有序性),以及一个写操作是否同时被其他处理器观察到(即可见性)。
- Memory Ordering
Load-LoadOrder:不同地址上的读操作会否乱序Load-StoreOrder:读操作和后面另一个地址上的写操作会否乱序Store-LoadOrder:写操作和后面的读操作会否乱序Store-StoreOrder:不同地址上的写操作会否乱序
- Store Atomicity
Load Other's Store Early && Non-Causality:允许写操作被自己及个别其他处理器先看到,不支持Causality。写序列可能以不同顺序被多个处理器观察到Load Other's Store Early && Causality:允许写操作被自己及个别其他处理器先看到,支持 CausalityLoad Own Store Early:只允许写操作被自己先看到。写序列以相同顺序被多个处理器观察到Atomic Store:所有处理器同时看到写操作
C++中的内存模型
Linux Kernel和高级语言标准都定义了自己的Memory Model,其中有专门的同步操作用于线程间协作。编译器负责将这个抽象的Memory Model映射到目标多处理器上,如果多处理器自己的Memory Model相对更强,那么上层Memory Model的同步操作可能退化成普通的存储器访问;如果目标多处理器的Memory Model相对更弱,则部分上层同步操作可能生成处理器提供的Barrier或Atomic指令来强制顺序和写原子性。
在C++11标准的atomic库中提供了std::memory_order,对于std::atomic变量的操作,指定参数来指定某种顺序或原子性
std::memory_order_relaxed:仅保持变量自身读写的相对顺序std::memory_order_consume:依赖于该读操作的后续读写,不能往前乱序;另一个线程std::memory_order_release之前的相关写序列,在std::memory_order_consume同步之后对当前线程可见std::memory_order_acquire:之后的读写不能往前乱序;另一个线程上std::memory_order_release之前的写序列,在std::memory_order_acquire同步之后对当前 线程可见std::memory_order_release:之前的读写不能往后乱序;之前的写序列,对使用 std::memory_order_acquire/std::memory_order_consume同步的线程可见std::memory_order_acq_rel:两边的读写不能跨过该操作乱序;写序列仅在同步线程之间可见std::memory_order_seq_cst:两边的读写不能跨过该操作乱序;写序列的顺序对所有线程 相同
通过指定这些内存序,就相当于程序员在这些位置进行了标记,告诉编译器和底层系统不要进行某种乱序,而在其他地方可以进行优化。从而能够最大限度保留编译器和多处理器的优化能力,同时使多线程程序的执行结果是可预测的。
使用内存模型解决上面提到的乱序问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int x = 0;
int r1 = 0, r2 = 0;
std::atomic<int> y;
void thread1Fun()
{
x = 1;
r1 = y.load(std::memory_order_release);
}
void thread2Fun()
{
y.store(1, std::memory_order_acquire);
r2 = x;
}
再看一个自旋锁的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class SpinLock {
public:
void lock() {
for (;;) {
while (lock_.load(std::memory_order_relaxed));
if (!lock_.exchange(true, std::memory_order_acquire))
break;
}
}
void unlock() {
lock_.store(false, std::memory_order_release);
}
private:
std::atomic<bool> lock_ = { false };
};
内存模型使用,尤其是较宽松的内存序时候,需要程序员自己校验:在当前内存序下,各种可能允许的乱序是否会导致不正确的结果,因此使用较为复杂。在这个自选锁的例子中,需要做以下自检:
加锁之后,临界区的数据会乱序到外面吗?———lock的最后一个操作是 std::memory_order_acquire,避免了向前乱序;unlock的最后一条操作是 std::memory_order_release,避免了向后乱序
允许临界区外的数据乱序到临界区里面吗? ———lock中只有 std::memory_order_acquire,故允许前面的代码向后乱序;unlock中只有 std::memory_order_release,故允许后面的代码向前乱序。
成员变量
lock_可见性? ——单个std::atomic变量的读写不被乱序且可见。
使用总结
SMP的硬件基础上,在多线程编程中,由于线程调度、中断,编译器以及硬件的优化会造成原子性、乱序、可见性三个问题:
加锁:加锁可以解决全部问题。锁保证了同一时间只有一个线程可以执行,解决了原子性和线程间乱序,同时加锁解锁也有内存屏障的语意或实现,也不会有可见性的问题。
原子指令:一些共享变量的使用可以考虑使用原子指令,如
int cnt; cnt++这种操作,使用atomic提供的原子类替换,原子类提供了原子性和可见性的保证,单个变量也不存在乱序的问题。内存模型:线程中多个共享变量的乱序性,或者一些
lock-free编程的实现,就要使用内存模型结合一些原子类并使用提供的内存序来解决这些问题。相比锁的开销更小,但内存模型的使用最为复杂,需要考虑各种可能存在的乱序、可见性问题,需要充分的校验。