内核kswapd进程分析

在第一篇博客记录了Unix Domain Socket的使用以及遇到的问题,文章的最后遗留了一个问题:使用UDP模式下,当操作系统内存处于较低水准时,send发送大块内存经常失败,返回错误:no buffer space available。除此之外,最近在线上服务器的高峰期,偶尔有记录到kswapd0/1这两个内核进程长时间运行,占用了相当一部分CPU和磁盘资源。
很显然,上面这两个问题与操作系统内存管理(分配、回收)息息相关,这篇文章简单记录下问题的分析及内核内存管理的部分知识的学习。
操作系统内存管理体系
目前绝大部分的操作系统采用的内存管理模式都是以分页内存为基础的虚拟内存机制。操作系统将内存以页作为分配和管理的单位,一页的大小通常是4KB大小。用户进程运行在虚拟内存中,使用的是虚拟地址,每个进程都拥有内核为之分配的页表集,记录了虚拟内存页到物理内存页的映射,当CPU执行指令执行使用到内存地址时,会利用硬件MMU(Memory Management Unit)以及进程自己的页表转换为物理地址,当页表中映射不存在时,就会发生缺页中断(Page Fault),内核会为该进程分配真正的物理内存,并更新页表。那么最终分配物理内存的是内核,内核又是如何管理物理内存页的呢? 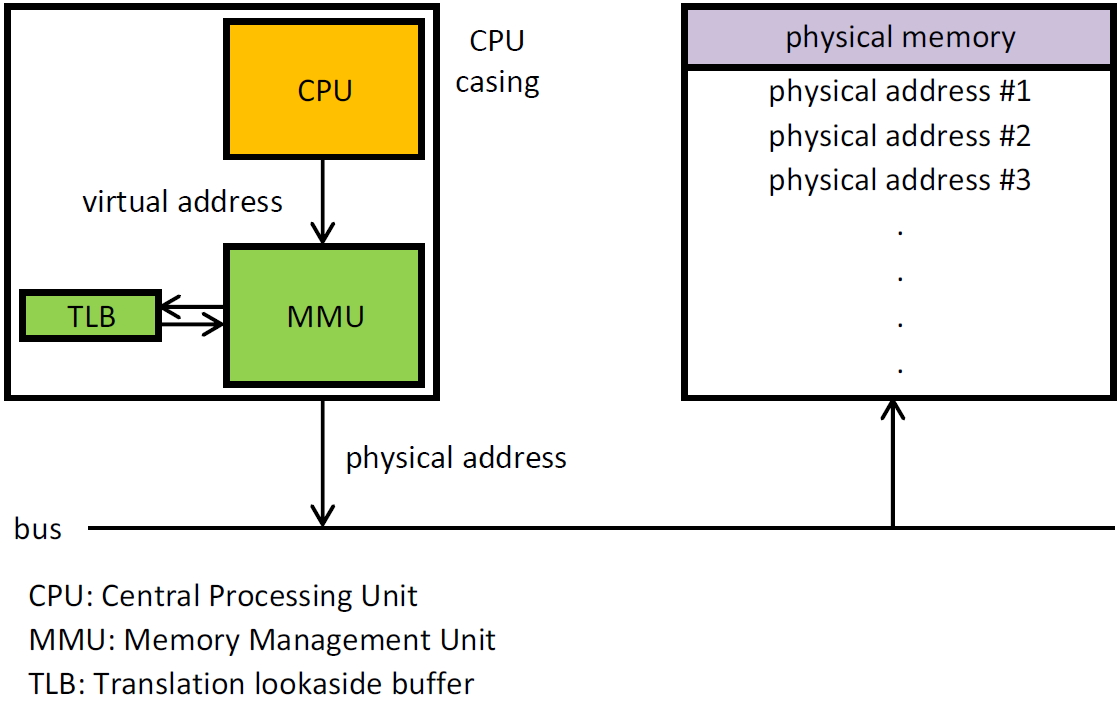
物理内存区域划分
内核把所有物理内存划分了两个层级进行管理,分别是node和zone,划分的原因与硬件相关。
- node:随着计算机CPU核数和算力的不断增强,单一的内存总线就会使得访问内存成为系统的瓶颈,因此发展出了
NUMA(Non-uniform Memory Access)架构,将CPU和内存划分为多个节点(node),CPU优先使用和分配当前节点的内存,从而缓解这个问题。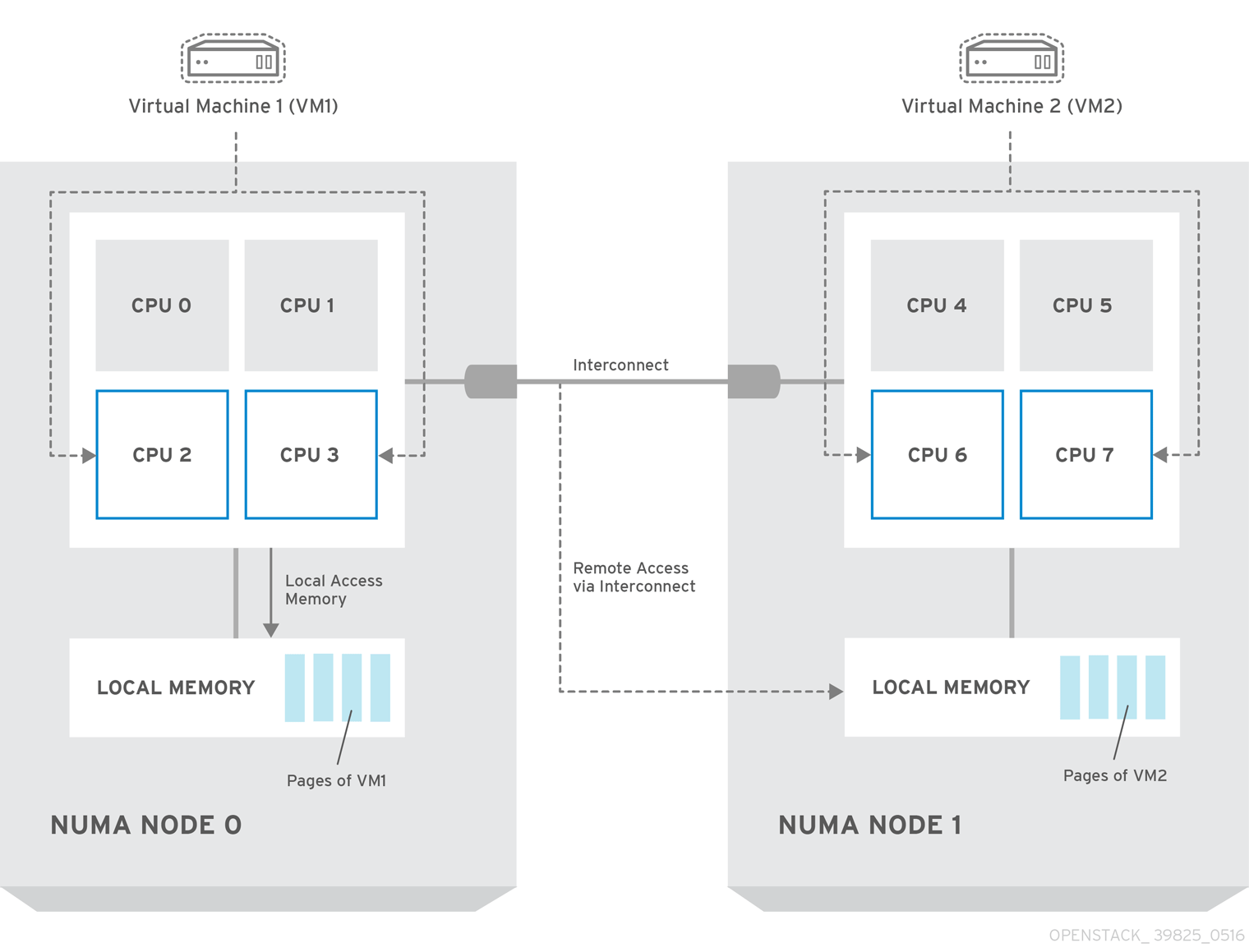 比如我的服务器就是两个node,可以使用
比如我的服务器就是两个node,可以使用numastat命令查看:1 2 3 4 5 6 7 8 9
rongchangyu:~$ numastat -v Node 0 Node 1 Total --------------- --------------- --------------- Numa_Hit 968210261.30 1005455923.13 1973666184.44 Numa_Miss 7764827.36 95644479.26 103409306.62 Numa_Foreign 95644479.26 7764827.36 103409306.62 Interleave_Hit 1642.77 1317.27 2960.04 Local_Node 968169560.45 1005410365.26 1973579925.71 Other_Node 7805528.21 95690037.13 103495565.35
- zone: node之下又划分为多个区域(zone)。分别有
ZONE_DMA、ZONE_DMA32、ZONE_NORMAL、ZONE_HIGHMEM、ZONE_MOVABLE、ZONE_DEVICE,划分的原因也与硬件特性有关。比如在x86上DMA内存区域是物理内存的前16M,这是因为早期的ISA总线上的DMA控制器只有24根地址总线,只能访问16M物理内存。并不是一个节点上要包含所有区域类型,可以通过/proc/zoneinfo查看:1 2 3 4 5 6 7 8 9 10 11 12
rongchangyu:~$ cat /proc/zoneinfo Node 0, zone DMA ... Node 0, zone DMA32 ... Node 0, zone Normal ... Node 0, zone Movable ... Node 1, zone Normal ... Node 1, zone Movable
就像是国家划分了省和市,每个市有自己的市政单位,优先负责本市的事务。内存也是一样,通常区域都有一个内存分配系统,负责内存的分配工作。
物理内存分配系统
分配系统负责页帧的分配,Linux采用的算法叫作伙伴分配系统(Buddy System),负责所有物理页面的分配工作,但只有伙伴系统还不行,因为伙伴系统进行的是大粒度的分配,还需要批发与零售,于是便有了Slab Allocator和Kmalloc。 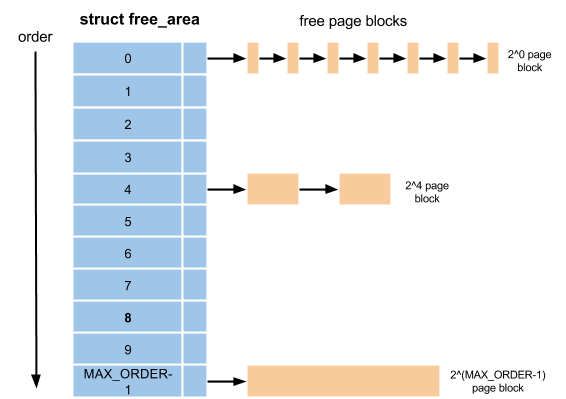
如上图为内存的组织方式,共分了11阶,最小内存块为2^0就是1页大小。最大内存块为2^10就是1024个内存页大小。
伙伴系统对外提供的接口只能分配某一阶的页块,并不能随意分配若干个页帧。当分配n阶页块时,伙伴系统会优先查找n阶页块的链表,如果不为空的话就拿出来一个分配。如果为空的就去找n+1阶页块的链表,如果不为空的话,就拿出来一个,并分成两个n阶页块。如果n+1找不到就继续往上找,直到第10阶。
内存释放时同样会尝试将当前内存块与相邻地址内存进行合并,2块并为一块放到更高阶的内存链表中。
物理内存回收系统
我们知道,虚拟系统使得用户进程可以使用的内存大于实际物理内存,通过换入/换出的技术保证进程的正常运行。同时在读写文件时,内核会将磁盘文件缓存到内存中,减少磁盘的IO,加速文件的读写。那么进程内存什么时候会被换出以及这些文件缓存什么时候会被释放就取决于内核的内存回收系统。
内存水位
前面讲了内存被划分为区域zone,每个区域管理一定大小的内存,就像一个大水缸。在水缸中划了三条线用于内存的监控、回收与安全,分别为high、low与min。具体每个水位线到总内存的多少比例跟系统参数有关,比如内存位于高水位线以上,那么代表内存充足,内存低于高水位高于低水位,则表示内存紧张可开启异步回收,当内存低于低水位线,表示内存告急直接进行同步回收。
上面讲的异步与同步是相对于内存申请的流程来说的,也就是说当调用函数申请内存时,会检查相关zone的水位线,并触发相应的异步/同步回收工作。
除此之外,即时水位线安全,但内存碎片化较严重,空闲内存无法满足当前申请内存块的大小时,也会触发内存回收工作。
kswapd
上面说的异步回收怎么做呢?开启一个新线程进行内存回收吗,不是的。内核在启动之时就创建了一些内核进程,其中一类就是kswapd进程,负责每个节点内的内存的回收工作,就是说我服务器分为两个node,那么就有两个内存回收进程:kswapd0、kswapd1。
当调用buddy system的接口分配内存时,会遍历可用zone尝试分配内存,当所有zone的内存水位线都低于低水位或分配失败时,会唤醒kswapd进程。
kswapd会展开内存回收工作,其中包括:扫描文件内存页,如果为脏页则写回磁盘并回收,干净页则直接回收;扫描匿名内存页,写到磁盘的swap分区并回收。因此当kswapd进程频繁持续运行时,会占用CPU、磁盘资源。 ![kswapd/assets/img/posts/kswapd.png)
遇到的问题
一般来说物理内存由内核管理,物理内存的分配、管理、回收对于用户进程来说都是透明、无感的。但当内存不够充足时,会有内存申请失败造成的接口调用失败、内存回收对系统资源的占用,严重时甚至导致系统负载过高、无法正常响应以及OOM的发生。
申请失败
回头再看文章开头我遇到的问题:no buffer space available。我在第一篇博客中并不清楚操作系统的内存管理体系,只是最后追踪到kmalloc这个申请物理内存的函数。现在来看,原因就是当内存空闲量较低时,通常内存碎片化也很严重,申请大块内存容易失败。在这篇博客中最大申请的buddy system中最高阶的内存块。可以通过/proc/buddyinfo查看当前系统内存块分布情况:
1
2
3
4
5
rongchangyu:~$ cat /proc/buddyinfo
Node 0, zone DMA 1 1 1 0 2 1 1 0 1 1 3
Node 0, zone DMA32 19232 16880 14263 3761 2400 1779 236 1 0 0 0
Node 0, zone Normal 122608 202664 48104 1 1 1 1 1 1 0 0
Node 1, zone Normal 135170 244079 96153 61 0 1 1 1 1 0 0
可以看到系统的高阶内存块相对来说还是比较稀缺的。
kswapd频繁运行
kswapd频繁运行会占用较多的系统资源,对系统运行造成影响。导致这一原因无非就是内存紧张,直接扩容内存可以一步到位解决问题。
但除了这么做还可以具体分析,是否有经常申请大块内存的动作;关闭swap分区;调整内存水位线等等措施。